以下文章有任何問題,都歡迎私訊我IG
我IG
在資料處理過程中,缺失值 (NAN) 是我們經常遇到的問題。今天,我們將以 Iris 資料集為例,針對四個不同的缺失值,使用四種不同的方法來處理,包括:
大家可以先將昨天的資料變成 Excel 檔案後,手動刪除以下數字,再儲存為 CSV 檔案,並命名為 iris_dataset01。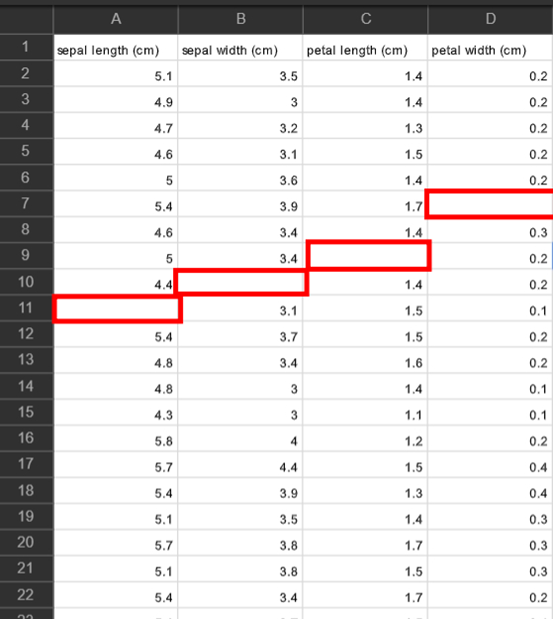
接下來,我們在同一個資料夾中建立一個新的 Google Colab 筆記本,命名為 iris_NAN。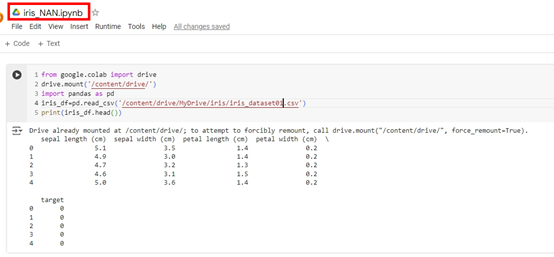
from google.colab import drive
import pandas as pd
# 掛載 Google Drive
drive.mount('/content/drive/')
# 讀取 CSV 檔案
iris_df = pd.read_csv('/content/drive/MyDrive/iris/iris_dataset01.csv')
print(iris_df.head())
首先,我們來檢查資料中的缺失值情況:
# 檢查資料集中每個欄位的缺失值數量
print(iris_df.isnull().sum())
這段程式碼會顯示每個欄位中缺失值的數量,幫助我們了解資料集的缺失情況。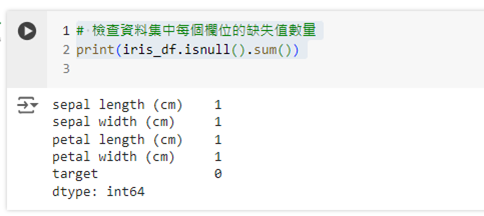
第一個方法是使用 dropna() 來完全刪除含有缺失值的行。這種方法適合當缺失值很少且刪除不會影響資料集的代表性時使用。
# 刪除含有缺失值的資料
iris_dropped = iris_df.dropna()
print("刪除含有缺失值的資料後的資料集:")
print(iris_dropped.head())
這段程式碼會將所有包含缺失值的行刪除,適合於缺失值數量很少的情況。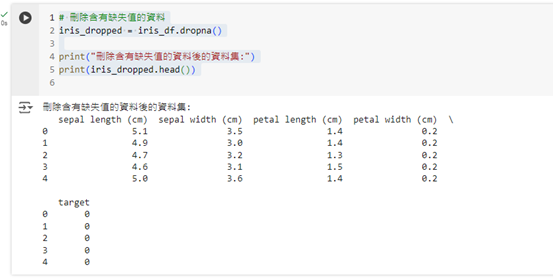
對於數值型資料,一個常見的方式是使用該欄位的平均值來填補缺失值。這種方法適合那些變數有相對穩定的分佈且缺失比例不大的情況。
# 用平均值填補缺失值
iris_filled_mean = iris_df.copy()
iris_filled_mean['sepal length (cm)'] = iris_filled_mean['sepal length (cm)'].fillna(iris_filled_mean['sepal length (cm)'].mean())
print("使用平均值填補'sepal length (cm)'缺失值:")
print(iris_filled_mean.head())
這段程式碼會將 sepal length (cm) 中的缺失值填補為該欄位的平均值。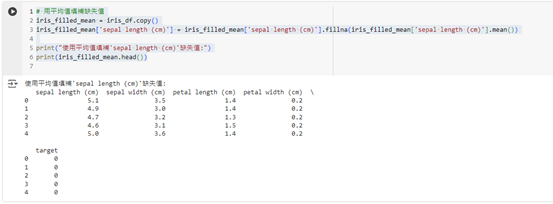
對於分類型或數值型資料,我們還可以使用眾數來填補缺失值。眾數代表在該欄位中出現最多次的值,這種方法適合用於類別變數或離散型數據。
# 用眾數填補缺失值
iris_filled_mode = iris_df.copy()
iris_filled_mode['sepal width (cm)'] = iris_filled_mode['sepal width (cm)'].fillna(iris_filled_mode['sepal width (cm)'].mode()[0])
print("使用眾數填補'sepal width (cm)'缺失值:")
print(iris_filled_mode.head())
這段程式碼會將 sepal width (cm) 中的缺失值填補為該欄位的眾數。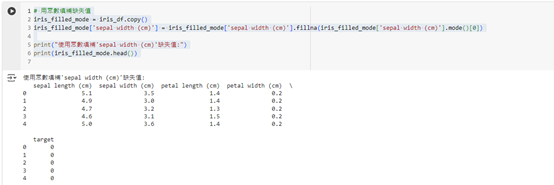
最後,我們可以選擇其他方式來處理缺失值,例如使用插值方法或固定值填補。這裡我們將使用插值來填補 petal length (cm) 的缺失值。
# 使用插值法填補缺失值
iris_filled_interpolate = iris_df.copy()
iris_filled_interpolate['petal length (cm)'] = iris_filled_interpolate['petal length (cm)'].interpolate()
print("使用插值法填補'petal length (cm)'缺失值:")
print(iris_filled_interpolate.head())
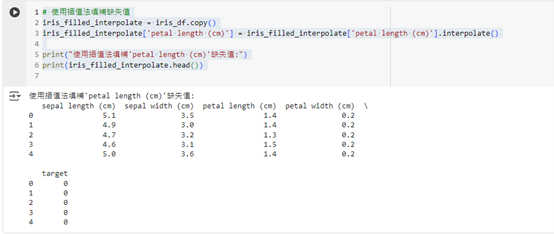
這段程式碼會使用線性插值方法來填補 petal length (cm) 中的缺失值,這種方法通常適合時間序列資料,但也可以在數據平滑過程中使用。
今天我們學習了四種處理缺失值的常見方法,並在 Iris 資料集中進行實際操作:
dropna())。fillna(mean))。fillna(mode))。interpolate() 或固定值)。處理缺失值是資料清理過程中的關鍵步驟,選擇適合的方法將有助於提高資料的完整性和分析的準確性。接下來,我們將學習如何處理資料中的異常值和重複值。


 iThome鐵人賽
iThome鐵人賽